
One of the goals of any publisher monetizing their website with ads is to rank as high as possible in the search engines. However, before this can happen, the page must be crawled and indexed. The two processes are decisive moments that determine every site’s position in search engine rankings. In this article, you will learn more about crawling and indexing, as well as how you can optimize your site for them. We will also explain some of the most important terms related to these processes, like spiders (web crawlers)!

How does Google Search work
Before we move on to explaining the differences between crawling and indexing, it’s worth knowing the definitions of the steps that lead to positioning and displaying pages in the biggest search engine – Google:
- Crawling is the first step in the process, which focuses on discovering, scanning, and downloading content from websites, including images, videos, PDFs, and articles. This work is done by spiders (other known as crawlers);
- Indexing’s primary goal is to analyze the content and the meaning of what was crawled in the previous step. Afterward, this data is stored in Google index – a database;
- Displaying search results is the last step in the process. Google aims to show users the most relevant matches to their query.
Indexing vs crawling
Crawling, as already mentioned, concentrates on finding, scanning, and downloading web content. Notably, only publicly available sites are crawled, so spiders will not access content that’s “hidden” beneath the login page (in other words, available solely after you log in). In Google’s case, the crawler is called a Googlebot, and it has two main types. One of them is Googlebot Smartphone, which works on mobile devices, and Googlebot Desktop, which mimics a desktop user. Interestingly, to avoid overloading, Googlebot can’t crawl sites too fast; the average time is a few seconds, but it’s unique to each site.
Spiders (web crawlers) access your pages, read the content, and follow internal and external links during their crawl cycles. They repeat this process, moving from one link to another until they have crawled a significant portion of your site. While this can cover all URLs on small sites, bots will only continue crawling on big or frequently updated sites until their crawl budget (the time and resources allocated by Google for crawling a website) is exhausted. The company states that this can mainly affect sites with more than 1 million unique pages updated once a week or ones with more than 10,000 unique pages updated daily. Another type of site it may concern is sites where lots of pages haven’t been crawled yet due to the threat of their overload.
Indexing happens after crawling and involves analyzing and storing information acquired during the first step of the process. Vitaly, it usually takes place right after it, but it’s not guaranteed. This phase includes analyzing content tags and attributes like alt descriptions, keywords, page structure, videos, graphics, etc. and checking whether the page is plagiarized. After Google decides that a page is canonical, which means original, it’s sent to an extensive library – Google index – with billions of websites. It’s worth knowing that not every web page gets indexed, as search engines prioritize pages they consider relevant and important.
How to get Google to recrawl your site
After making some significant changes or adding new content, it’s advisable to get Google to crawl and index your site once again. There are two main ways to do that, depending on the number of URLs you’d like to be analyzed:
-
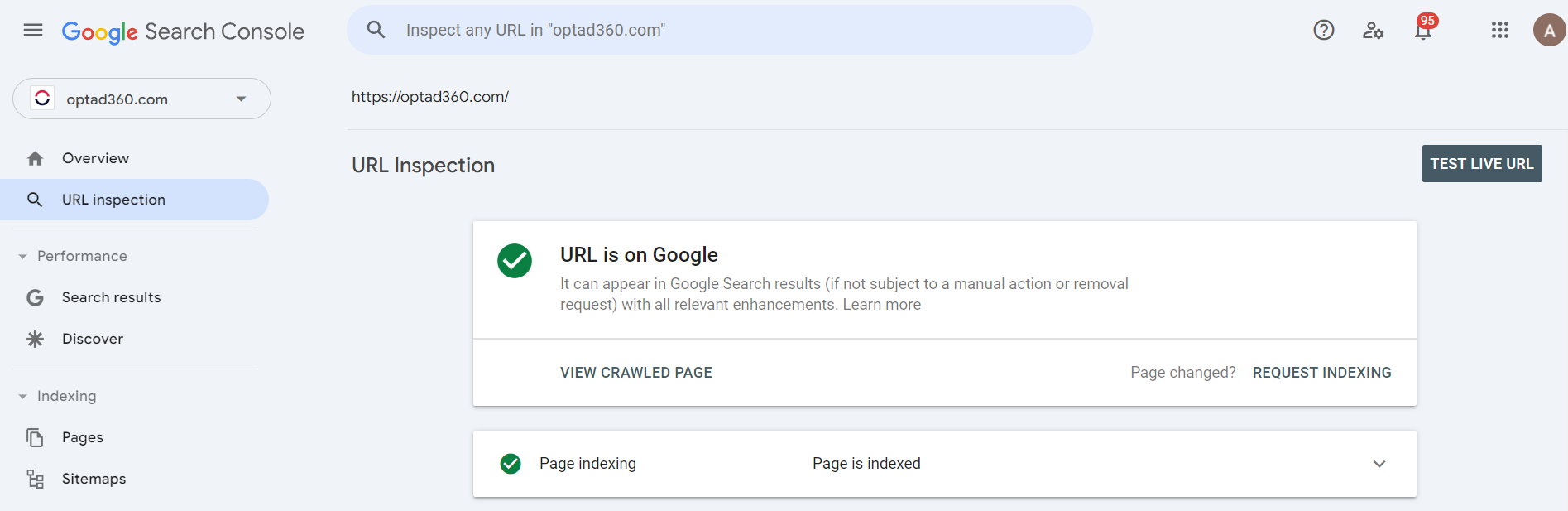
- In case a small number of URLs need to undergo the process again, you can use the URL Inspection Tool. However, to do that, you will need Search Console property access, which means you can be either its full user or owner. Here’s how you can submit your request:
- after signing in to the Google Search Console, paste your URL in the search bar at the top and click “Enter”. Then “REQUEST INDEXING” (this will also work if a page hasn’t been indexed yet),
- if it passes a check for possible indexing errors (in case some issues are detected, you will get a notification), it means that your page is waiting in line. Avoid submitting the same URLs over and over again because this won’t speed up the process;
- In case a small number of URLs need to undergo the process again, you can use the URL Inspection Tool. However, to do that, you will need Search Console property access, which means you can be either its full user or owner. Here’s how you can submit your request:
- When you need to do that for more URLs at once, you can submit a sitemap. It’s a file containing details about your site’s contents and connections between them. Just keep in mind that even after submitting it, it’s not guaranteed that all your pages will undergo the process. You can either create it or, in some cases, even find a ready-to-use one. In order to submit your map, you have to indicate the path to your sitemap by altering and adding a line like this to your robots.txt file: https://website-example.com/my_sitemap.xml.
Tips for optimizing your website for crawling and indexing
-
- Make sure that the pages you intend to be indexed are actually undergoing the process (you can do so in Google Search Console, like in the steps described above, and request indexing if you notice your website hasn’t been indexed);
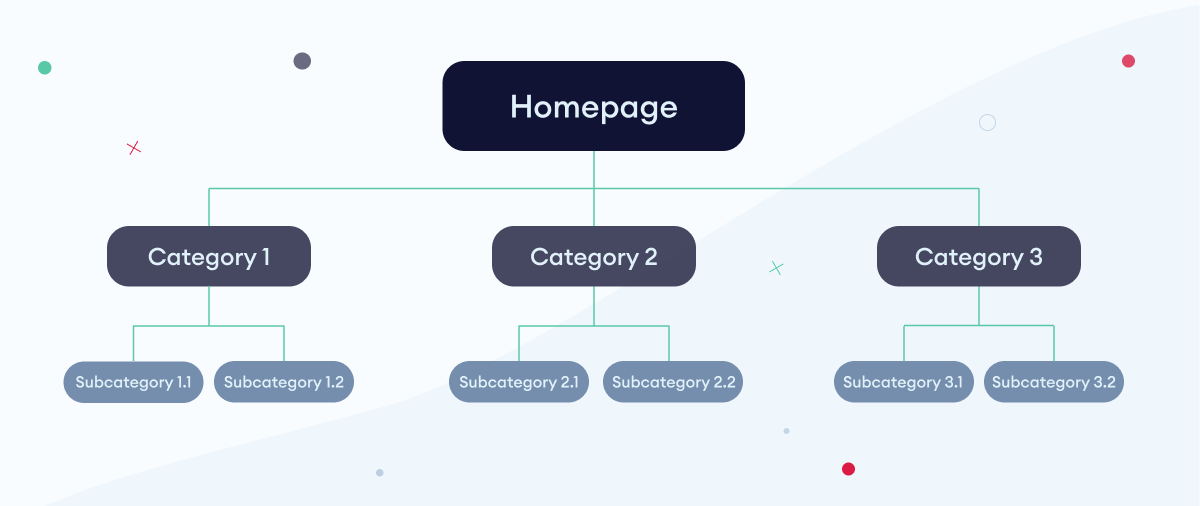
- Optimize site structure if it’s not logical. It is best if it has a traditional pyramid structure, which looks like on the graphic below:
- Try to speed up your site – it can’t be loading for too long because crawlers won’t crawl as much as they could because of their time limits for each website. Additionally, you should read our article about Core Web Vitals, where we disclose other reasons why loading speed is crucial;
- Incorporate internal links on your website, that will enable crawlers to pass between your pages;
- If your site isn’t responsive – try to fix it immediately. Since 2016 Google has opted for mobile-first indexing, which means extra attention is paid to mobile versions of websites;
- Don’t allow broken links to mislead Googlebot. Detect 404 errors on your site, and remove or update those pages;
- Use robots.txt if you want to block some sections of your website, but make sure that you haven’t denied access to all pages;
- Produce only quality content. Google values uniqueness and usefulness and puts the needs of the user first.
Optimize and then monetize
Crawling and indexing are two distinct yet crucial processes for effective SEO. While crawling ensures that search engines discover your site’s content, indexing involves analyzing the content to understand its relevance and meaning. For effective Search Engine Optimization, don’t forget to optimize your site to ensure it is easily crawled and correctly indexed. Once you take these steps, don’t hesitate and make your content generate income for you! To get help with this task, familiarize yourself with the requirements to join the optAd360 network, fill in the registration form, and hop on our board!
Read also

Content decay and how not to let your work rot
Don’t let content decay haunt your website, discover how to turn it into a growth adventure instead!
Read more
Have you ever noticed, that some of the queries typed into a search engine, get a response displayed just below the search box? These pieces of information are known as featured snippets – a great opportunity for every digital content creator!
Read more